on
The Database Streamy Weamy Pattern
A few years ago I was introduced to an interesting ebook called Designing Event Driven Systems. In it the author Ben Stopford outlines how to build business systems using Apache Kafka. I was a young impressionable developer and the book turned my understanding of system design on its head.
At the time I was working at a small software monitoring company. Our system took in hundreds, sometimes thousands, of requests per second. We stored terabytes of error payloads and user events. The company was growing and scale was an issue. As I read the book on the way to and from work I got excited. I sketched out a few proposals for us. We could use Kafka to scale up our data processing!
I brought my ideas to my colleagues and boss, all developers. No one was interested. It was too hard to move away from our kludge of SQL databases to a stream-based architecture. Somewhat disappointed, I discarded the notion of ever using Kafka there.
Yet my colleagues had a fair point. Organisations will find it challenging and expensive to move from monolithic SQL databases to streaming. It usually isn’t a good idea to change your architecture in one big bang. You need to transition slowly.
As I learnt more about streaming a particular pattern caught my attention. It is a way to replicate your database in a streaming platform like Kafka. People have done this before. But no one has named it yet. So I took it upon myself to label it the database streamy weamy pattern.
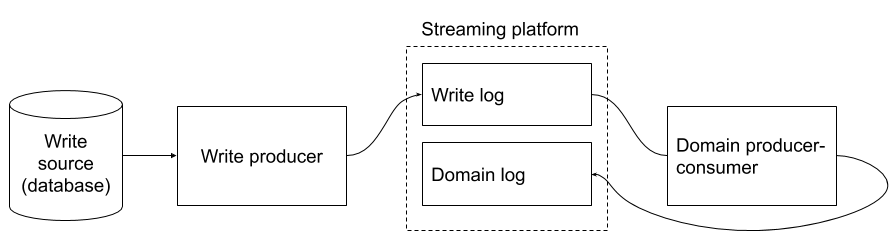 Five components of the streamy weamy
Five components of the streamy weamy
With the the database streamy weamy you pull the data you want from your database onto a distributed log (i.e. Kafka). You get to keep your existing SQL database and do not have to change its logic. By reading from the distributed log instead of the database, you open up a world of opportunities for new applications. The streamy weamy gives you a taste of the streaming life without changing your reliable SQL database.
When you update or delete a table in your database, a log event is written to your streaming platform. You convert the raw SQL events (update this field, delete this row, etc.) to a nicer format that suits your domain (this customer bought that, this user did this). Domain events are written to the domain log. You can subscribe to the domain log to cache data, analyse it, or do whatever it is you are interested in. No talking to the database.
Let’s look at the five components of the streamy weamy.
Write source
This is your SQL database and a plugin that reads all entries in the write-ahead log (WAL) in real time. A relational database records all table changes (updates, deletes) in the WAL. Many DBMS’s support streaming from the WAL. In Postgres it is called logical decoding. And change-data capture in Microsoft SQL Server.
 Write source with patient and appointment tables as examples
Write source with patient and appointment tables as examples
There are some basic requirements for the write source. It must
- precisely describe the database update that occurred e.g. which table, which row, what the current columns values are, etc.
- produce each change in real time.
- produce each change in serialised order (the order in which it occurred).
- keep the track of the current position in the log.
Write producer
A little application that connects to the write source. Your write source (the database) will feed events to the write producer. The write producer parses events from the write source and converts them to a better format for the write event log. It is a good idea to define a schema for your write event log. But you can simply publish the raw events that the write source gives you.
The write producer does not perform any business logic. It takes write events from the write source, converts them as necessary, and publishes them to the write log. And there are some opportunities for optimisation.
Your write producer must:
- correctly parse each event from the write source. Read the documentation carefully for the format for your WAL plugin.
- not lag behind the write source. If you are unable to keep up with the volume of writes from the write source, resources will be used storing changes in the WAL.
- not have application errors and be able to recover if a failure occurs. It would be nice if all software was bug free. But it is particularly important here that the write source work as reliably as your DBMS. Keep it simple and test it well.
Write event log
This will be a topic in your streaming platform. Kafka is ideal here. You could publish the raw write source payloads. But a schema is a good idea. It doesn’t need to be complicated. Just model the structure of an SQL write event. The write event log is effectively a replica stream of your database.
{
"change": [
{
"kind": "insert",
"schema": "public",
"table": "appointments",
"columnnames": ["id", "staff_id", "patient_id", "appointment_time", "status"],
"columntypes": ["integer", "integer", "integer", "timestamp without time zone", "text"],
"columnvalues": [12001, 101, 8511, "2019-10-03 09:30:00.000000", "confirmed"]
}
]
}
An example payload from the Postgres wal2json plugin.
Fields for topic schema may include: database name, table name, column names, column data types, row data, the operation type (insert, update, delete), timestamp, global index, raw SQL, etc. Make sure your schema accurately captures the database model.
Domain consumer-producer
Now we breathe life into the data events. Like the write producer, events go in one end of the domain consumer-producer and new events come out. But your domain consumer-producer may apply some business logic to the event stream. The events that come out will be about the domain of your organisation.
Consider a the booking system for a clinic with multiple doctors and nurses on site. Suppose the following event comes through. Breaking down the event we can see that it is a new appointment. A patient is seeing a staff member at 9:30 on 3rd October 2019. The record in this example has a confirmed status.
{
"type": "event",
"entity": "appointment",
"index": 2004565,
"is_new": true,
"body": {
"id": 12001,
"patient": {
"id": 8511
},
"staff": {
"id": 101
},
"appointment_time": "2019-10-03T09:30:00+13:00",
"status": "confirmed"
}
}
In this example we have not transformed it much from the original SQL event. But we have made it into an easier JSON format to read. It is important to decouple your SQL database from the domain log. This will let you transition away from the SQL database.
Domain log
This is a topic, or set of topics, in your streaming platform. It stores the events from the domain producer. You must define a schema for this topic which you can share with others in your organisation. Ideally the schema should allow for extension as your business and business logic changes. The domain log is where the power of streaming gets put to use.

Other people in your organisation connect to and read the domain log to implement their own useful applications. So it is important to publish each topic’s schema for others to view. You should also make it easy for people to get authenticated access to the log. This will unlock opportunities for others to develop cool applications. The domain log is built for re-use, decentralisation, and innovation.
Now the fun begins
Suppose you work on this patient management system and want appointment alerts. Patients need to get a text message (SMS) alert or email when their appointment is confirmed. They also need a reminder 24 hours before the appointment. Let’s assign the mission to a pair of interns. The database streamy weamy will make it easy for them to build the alert generator.
The interns initialise a new project in their trendy language (Rust, JavaScript, Erlang?) and get to work. They write a program that consumes the appointment events from the appointment topic, sends messages for new appointments, and schedules 24-hour reminders. They use the schema you have published to read the appointment data.
The interns make zero changes to the big ball of mud booking system. Their focus is the reminder engine. It reads from one Kafka topic and performs a few simple functions. By the end of the summer the reminder engine is working in production. The interns return to university proud of their work.
The domain logs also lets you extend the functionality of the booking system. Consider an event like the Covid-19 pandemic. You now need to track whether the appointment is a Covid test. So you add an is_covid_test field to the appointment schema in the domain log. The alert system now asks in the email or text message if the booking is a Covid test. If the answer is yes, staff are informed. This allows them to be ready with PPE, hygiene protocols, and to perform the test in a safe location.
Now the not so fun challenges
This sounds great. We should make everything a streamy weamy! Though it is good there are challenges in implementing this pattern. Your database may be complex. Your organisation may be complexer. And there are trade-offs and fundamental constraints you have to design around.
Bottlenecks
The write producer may add overhead that consumes extra resources on your database server. Database writes must be shuffled from the write producer to the write event log as efficiently as possible. A replication lag will occur if the write source buffers more events than the write producer can handle. If the producer cannot keep up with volume, disk space will grow in an unbounded fashion. And downstream systems will have stale data. To mitigate this you will need to
- monitor the replication lag between the write source and write producer.
- stress test the database in a test environment. Define the maximum expected load and add a safety factor. Measure the performance of the write producer and streaming platform.
- use caching and compaction of similar or identical writes.
Your write producer must also be fault tolerant. Consider if the streaming platform goes offline. The write producer should wait patiently until it becomes reachable again. Similarly if the database connection fails, wait patiently and try again.
Global ordering
You want to divide your topics into partitions. In Kafka, partitions divide a topic (like appointments) into multiple logs. This allows you to scale up. But ordering is only guaranteed within a partition. There will be problems if you require a total order across partitions.
Look at the situation below. Cache worker 0 is running a little late. It is about to cache the data for appointment 90374. But cache worker 1 has already seen the newer appointment update (with change index 2) and published it to Redis. Thus the cache is going to show the wrong appointment time of 09:30.
 Appointment 90374 is about to be changed to the wrong time.
Appointment 90374 is about to be changed to the wrong time.
You therefore need an appropriate key for appointments. The obvious key is the appointment ID. This can be the database table’s primary key. Kafka delivers messages with the same key to the same partition. This keeps updates for the same appointment consistent. The consumer application will receive the events in the order they occurred. So the two domain log consumers will not conflict with each other.
Denormalising data
You might have a database that is normalised. Suppose the patient management system stores the core appointment information in the appointment table e.g. appointment time, staff ID, etc. And some optional details in appointment_details e.g. a note about the appointment. Consider when the patient adds this note:
update appointment_details set patient_notes = 'I need to talk to Dr Jackson about XYZ' where appointment_id = 12001
Let our domain log store all appointment information in a denormalised format. Including time, staff ID, and notes. When the patient notes are added the domain consumer-producer needs to publish an appointment event with the other fields to the domain log. To do so it keeps a cache of appointment information in memory or on disk. In effect it stores a partial replica.
When the update is published this cached data can be retrieved to publish the whole appointment. Another solution could be to fetch the other appointment data from the write source. If your write source is a replica then this could work fine. With the replica you have access to consistent data without having to read from the main database.
Eventual consistency
Eventual consistency means that eventually the system returns the result of the last commited write. When a change is committed to our write source it is propagated downstream. But it will be delayed by network latency, connection speed, and processing time. So downstream will see a snapshot of the “past” while the change makes its wee way through the system. As long as the propagation delay is low this is not a problem. The latest updates will come through eventually.
The entire streamy weamy pattern assumes you can tolerate or mitigate eventual consistency. The CAP-thereom means that trade-offs must be made between partition tolerance, availability, and strong consistency. In short you can pick two of these. With strong consistency ruled out we get to pick the other two. A correctly-configured Kafka cluster can tolerate a network partition. And if a node goes down data can still be available.
Conclusion
The database streamy weamy pattern streamifies your database. This can allow you to scale. A raw write log and a more refined domain log decouple the database from the logs. With real-time data pushed to your domain log others can develop new business applications. There are trade-offs such as eventual consistency. Effort is required to ensure global ordering and denormalise your data. If you have wanted to develop an event-based architecture but do not want to write it from scratch, give the database streamy weamy a go.